X86 Instruction decoding
Contents
Overview
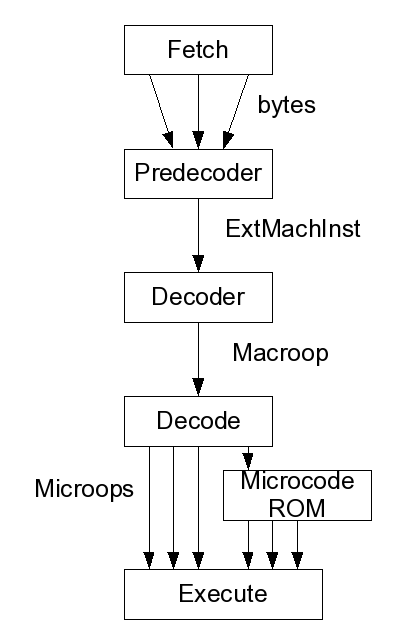
X86 instruction encodings have several unique characteristics which make them harder to deal with than the encodings for the other ISAs M5 supports. Despite that, x86 is decoded using the same basic mechanisms as the other ISAs.
At the lowest level, instructions can take any number of bytes (up to a maximum) and can have any alignment. That means that when a CPU brings in bytes of memory to decode, it may contain several instructions, the end of one and the start of the next, the middle of an instruction, etc. It's the predecoder's job to take the incoming stream of bytes and to turn them into a stream of objects, called ExtMachInsts, which represent the encoding of a single instruction from beginning to end in a unique and uniform way. The predecoder also makes the guarantee that if any two instruction representations are the same, the instruction object that implements it is also the same.
Next, the instruction representations need to be translated into an instruction object which the CPU can execute. This is the job of the x86 decoder which is implemented as ISA description files and automatically generated. In addition to the instruction objects and the decoder itself, a ROM object is defined which holds microops which can be executed independent of any containing instruction.
Finally, the instruction object is handed back to the CPU. If the object is a regular instruction it can be executed directly. If the object is a macroop, aka a microcoded instruction, the CPU's decode section pulls microops out of it one at a time and actually executes those. Control flow within the microops may move execution out of the current macroop and into the ROM. If that happens, instructions are pulled from the ROM until the next instruction starts.
Predecoder
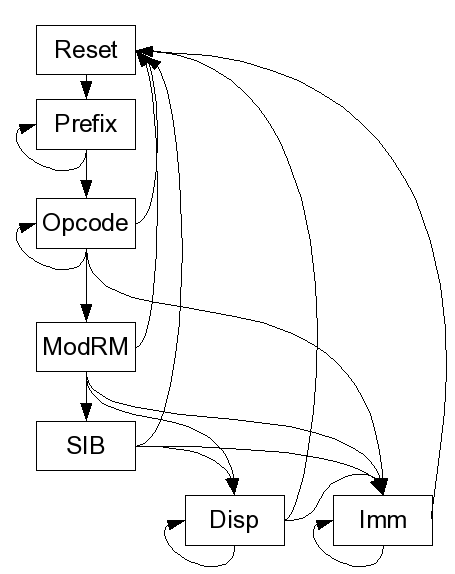
The diagram above shows the high level state machine that runs the x86 predecoder. The CPU feeds the predcoder bytes in certain sized chunks which, in other ISAs, would correspond with instructions. In x86 these are just bytes and are processed one at a time to move the predecoder through the state machine. The predecoder may not have to consume the entire chunk, or it may go through several before it has an entire instruction. Once it's finished, there should be a completed ExtMachInst representing one instruction ready for the CPU to use.
Reset State
Resets internal state to prepare for the next instruction.
Prefix State
Recognizes and records the various prefixes allowed for an instruction. When a byte comes in that is not recognized as a prefix, the machine goes to the Opcode state.
Opcode State
Gathers up all the bytes that represent the instructions opcode. Instructions can have 1, 2 or even 3 byte opcodes. This state also figures out how many bytes of immediate value, if any will be part of this instruction, and what the default address size, operand size, and stack size are. If this instruction uses a modRM byte, the next state is ModRM. Failing that, if there are any immediate bytes to collect, the next state is Imm. If neither of those are true, then the instruction has been gathered and the machine resets.
ModRM State
Processes the modRM byte. This includes determining which registers will be used as part of address computation or as operands directly, and how many, if any, bytes will be used for the displacement. This state also determines whether to expect an SIB byte. If so, the next state is SIB. If not and there are displacement bytes to collect, the next state is Disp. If not and there are immediate bytes to collect (as determined in the Opcode state), the next state is Imm. Otherwise, this instruction is finished.
SIB State
Very similar to the ModRM except processing the SIB byte.
Disp State
Collects as many displacement bytes as it can from the bytes provided by the CPU. If the whole displacement has been collected, the state machine continues on to Imm if immediate bytes are needed, or it completes the current instruction.
Imm State
The same as Disp except for immediate bytes.
Decoder generation
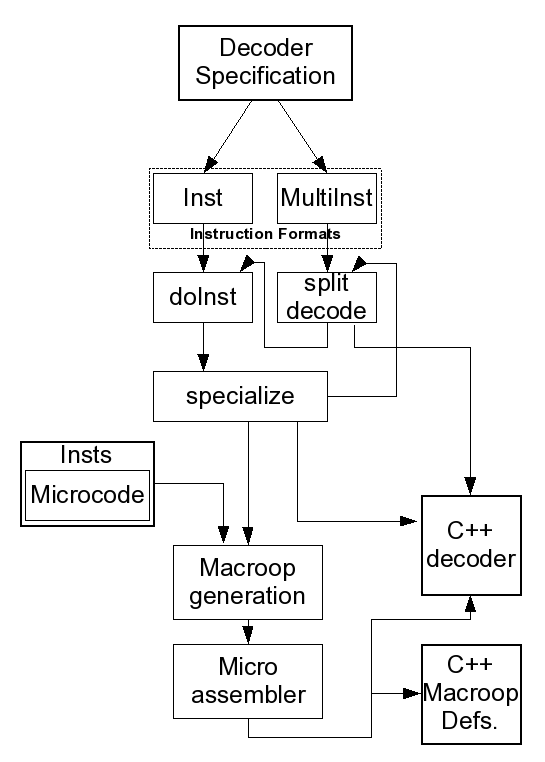
X86's decoder is generated using an ISA description like all the other ISAs, although how it does that is a bit different. Most of the instructions for most of the other ISAs are defined by passing chunks of code that perform the instruction into an instruction format. The format is basically a template which puts wraps that bit of code in the structure needed to support it and you have your instruction object. Because almost all of the instructions in x86 are microcoded and many can be encoded in multiple ways and hence appear in the decoder more than once, and because the same non-trivial decoding rules apply to many different instructions, X86 uses the decoder as a layer of indirection and defines the majority of its instructions elsewhere.
X86 almost exclusively uses only two different instruction formats, Inst and MultiInst. MultiInst is just a compact way of describing multiple related Insts. An Inst essentially selects an instruction like XOR and provides a specification for its operands. Inside the instruction format, the instruction name and operand specification are passed to a python function called "specializeInst" which figures out what to do with it. If the operand specification describes more than one version of the instruction, for instance one that uses memory and one that uses registers, the instruction's information is passed into another funciton, "doSplitDecode", which separates out those versions and passes each individually back through the same system. This goes on until the instructions have been fully split out and code has been generated to figure out what version to use. As a nice bonus, the MultiInst format doesn't add much complexity to this model since it can simply jump right into doSplitDecode and continue as normal. There is one additional format for string instructions that works similar to MultiInst, except instead of specializing the instruction based on its operands, it specializes it based on its prefixes. There are also a few instructions that don't use this system, but because there are so few and because they work like the instructions in other ISAs I won't describe them here.
At this point, the code for selecting the right version of an instruction is put into the C++ decoder function. Almost all of this function is built this way, with the minor exception of small bits of logic that glue everything together and make large scale distinctions the number of opcode bytes.
Now that we know -what- instruction we want, we need to actually generate a definition for it. Before this entire process got rolling, a library of macroops and their microcode definitions were assembled using the microcode assembler. The specialized name of the instruction/macroop, for instance XOR_R_R, or XOR with two register operands, is used to look up a python object in that library that describes how to implement XOR_R_R. This object has the smarts to generate the C++ needed to implement itself. That code is generated and stuck into source files, and a small bit of code is added to the decoder so that an instruction of the right type can be allocated and returned.